Lua Stack: Source Insight
Last updated: 2024/03/09 Published at: 2024/03/09
管中窥豹:从 Lua 调用 C
请先允许我复制并简单翻译下 Lua5.3 的官方文档中和栈相关的几个关键内容,文档的描述非常的精练,个人实在是不能描述的比文档更好了,所以请读者能原谅我这无耻的复制粘贴行为。由于我司目前的 Lua 环境仍旧是 Lua5.3,故以 Lua5.3 的源码作为实现的分析来源,实际上,我也对比了这一部分内容在 Lua5.4 中的相关实现,逻辑并没有大的变化,只是有一些数据结构定义上的变化和重构,因此以 Lua5.3 进行源代码的分析并不算过时。
4.1 The Stack
Lua uses a virtual stack to pass values to and from C. Each element in this stack represents a Lua value (nil, number, string, etc.). Functions in the API can access this stack through the Lua state parameter that they receive.
Lua 使用一个 虚拟栈 来和 C 互传值。栈上的的每个元素都是一个 Lua 值(nil,数字,字符串,等等)。
Whenever Lua calls C, the called function gets a new stack, which is independent of previous stacks and of stacks of C functions that are still active. This stack initially contains any arguments to the C function and it is where the C function can store temporary Lua values and must push its results to be returned to the caller (see
lua_CFunction).无论何时 Lua 调用 C,被调用的函数都得到一个新的栈,这个栈独立于 C 函数本身的栈,也独立于之前的 Lua 栈。它里面包含了 Lua 传递给 C 函数的所有参数,而 C 函数则把要返回的结果放入这个栈以返回给调用者(参见
lua_CFunction)。For convenience, most query operations in the API do not follow a strict stack discipline. Instead, they can refer to any element in the stack by using an index: A positive index represents an absolute stack position (starting at 1); a negative index represents an offset relative to the top of the stack. More specifically, if the stack has n elements, then index 1 represents the first element (that is, the element that was pushed onto the stack first) and index n represents the last element; index -1 also represents the last element (that is, the element at the top) and index -n represents the first element.
方便起见,所有针对栈的 API 查询操作都不严格遵循栈的操作规则。而是可以用一个 索引 来指向栈上的任何元素:正的索引指的是栈上的绝对位置(从 1 开始);负的索引则指从栈顶开始的偏移量。展开来说,如果堆栈有 n 个元素,那么索引 1 表示第一个元素(也就是最先被压栈的元素)而索引 n 则指最后一个元素;索引 -1 也是指最后一个元素(即栈顶的元素),索引 -n 是指第一个元素。
lua_CFunction
typedef int (*lua_CFunction) (lua_State *L);Type for C functions.
C 函数的类型。
In order to communicate properly with Lua, a C function must use the following protocol, which defines the way parameters and results are passed: a C function receives its arguments from Lua in its stack in direct order (the first argument is pushed first). So, when the function starts,
lua_gettop(L)returns the number of arguments received by the function. The first argument (if any) is at index 1 and its last argument is at indexlua_gettop(L). To return values to Lua, a C function just pushes them onto the stack, in direct order (the first result is pushed first), and returns the number of results. Any other value in the stack below the results will be properly discarded by Lua. Like a Lua function, a C function called by Lua can also return many results.为了正确的和 Lua 通讯,C 函数必须使用下列协议。这个协议定义了参数以及返回值传递方法:C 函数通过 Lua 中的栈来接受参数,参数以正序入栈(第一个参数首先入栈)。因此,当函数开始的时候,
lua_gettop(L)可以返回函数收到的参数个数。第一个参数(如果有的话)在索引 1 的地方,而最后一个参数在索引lua_gettop(L)处。当需要向 Lua 返回值的时候,C 函数只需要把它们以正序压到堆栈上(第一个返回值最先压入),然后返回这些返回值的个数。在这些返回值之下的,堆栈上的东西都会被 Lua 丢掉。和 Lua 函数一样,从 Lua 中调用 C 函数也可以有很多返回值。As an example, the following function receives a variable number of numeric arguments and returns their average and their sum:
下面这个例子中的函数将接收若干数字参数,并返回它们的平均数与和:
1static int foo (lua_State *L) { 2 int n = lua_gettop(L); /* number of arguments */ 3 lua_Number sum = 0.0; 4 int i; 5 for (i = 1; i <= n; i++) { 6 if (!lua_isnumber(L, i)) { 7 lua_pushliteral(L, "incorrect argument"); 8 lua_error(L); 9 } 10 sum += lua_tonumber(L, i); 11 } 12 lua_pushnumber(L, sum/n); /* first result */ 13 lua_pushnumber(L, sum); /* second result */ 14 return 2; /* number of results */ 15}
我在读完文档之后,还是有很多的疑惑:
- Lua 提供的 API 基本上都围绕 Virtual Stack 所设计,但是这个 Virtual Stack 到底代表了什么?既然取名为 Stack,那么这个 Stack 和 Lua 的运行时的堆栈有什么关系?Lua 为什么要这么设计?
- 第二段中提到,无论何时 Lua 调用 C,被调用的函数都得到一个新的栈,这又是如何做到的?这样做不会有很大的性能代价吗?
- 从给出的 C 例程看,从 Lua 代码中传入的参数,被依次压入到 Lua 提供的 Virtual Stack 中,C 层需要返回给 Lua 层的结果也被依次的压入该 Virtual Stack, 该函数在将结果推入栈之前不需要对栈进行额外的处理,这又是如何做到的?
And, you know, reading the source is of course the only way to enlightenment. 这句话摘自 LuaJIT 文档中的 FAQ, 可谓是振聋发聩。
Lua 的文档十分精练,可以说是点到为止,并不足以解决我的困惑,接下来,就让我们开启对源代码的探索之旅,揭开 Lua Stack 的神秘面纱吧!
渐入佳境:一探源码
在学习 Lua 的源码实现时,发现了一门非常有意思的课程 Run-Time Systems,里面的关于 Lua 的课程讲义,帮助了我很多,有兴趣的朋友也可以去瞧瞧。
可以看到,lua_State 这个结构体是用户和 Lua 交互的一个最重要的对象,从名字上看,它表示的是一个 Lua 程序的执行状态,不过本文关注的重点是 lua_State 里和 Virtual Stack 相关的部分。
lua_State中主要维护了两个栈。
- 数据栈:是
TValue对象的数组。Callinfo对象索引到这个数组中。 - 调用栈:是
Callinfo构成的一个双向链表,用来跟踪函数的调用栈 (activation frames)。
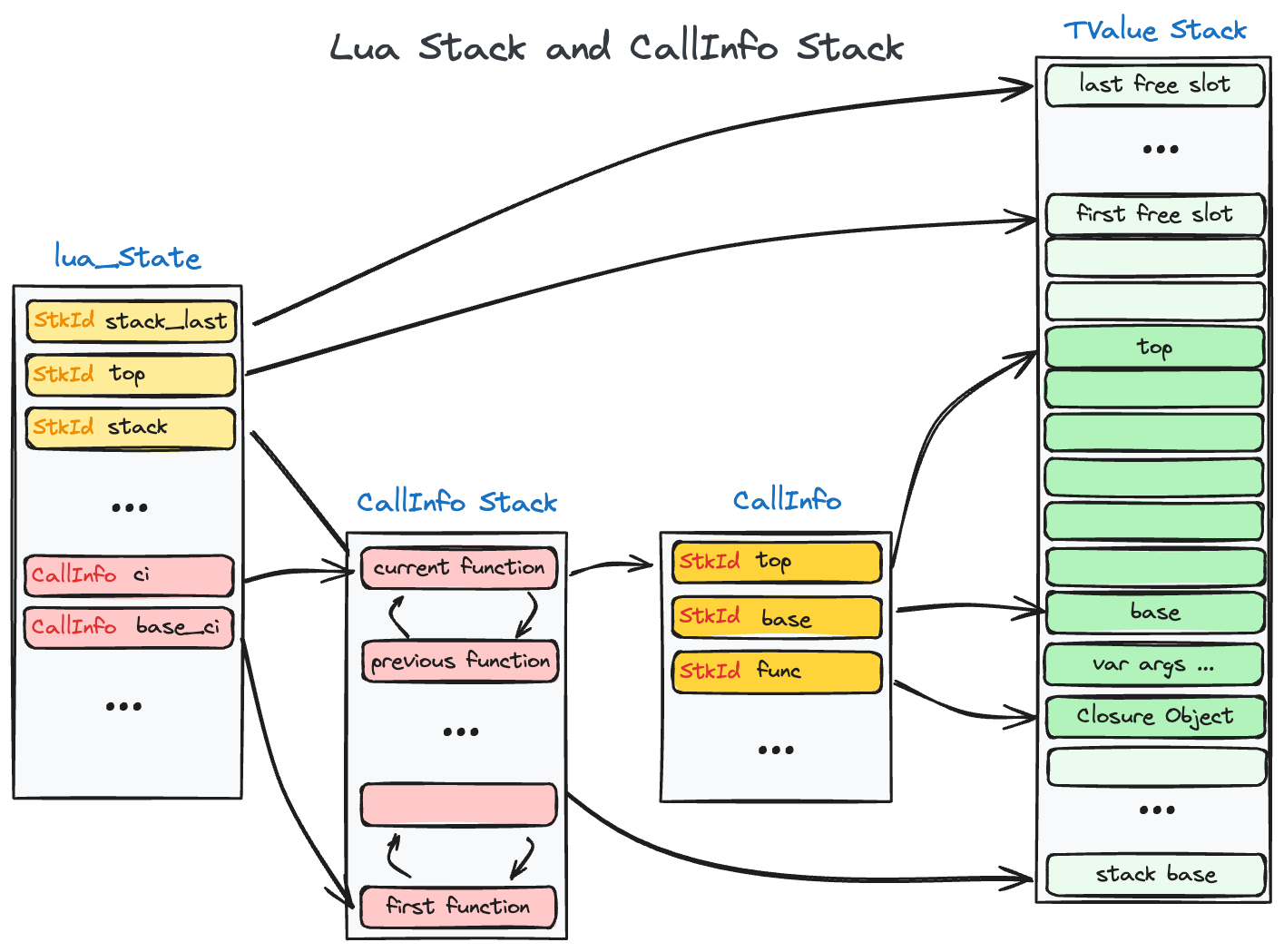
根据我对 Lua 中两种 Stack 的理解,绘制了这个大概的引用关系,不是特别精确,因为 Lua 不单纯是一门虚拟机语言,更是作为一门嵌入式语言而存在,C 和 Lua 互相调用也是常态,这里只给出 Lua 部分的堆栈变化,而 C 会对这些堆栈会产生什么影响,要等到讲到 Lua 的 Coroutine 才行。
lua_State
1struct lua_State {
2 CommonHeader;
3 unsigned short nci; /* number of items in 'ci' list */
4 lu_byte status;
5 StkId top; /* first free slot in the stack */
6 global_State *l_G;
7 CallInfo *ci; /* call info for current function */
8 const Instruction *oldpc; /* last pc traced */
9 StkId stack_last; /* last free slot in the stack */
10 StkId stack; /* stack base */
11 UpVal *openupval; /* list of open upvalues in this stack */
12 GCObject *gclist;
13 struct lua_State *twups; /* list of threads with open upvalues */
14 struct lua_longjmp *errorJmp; /* current error recover point */
15 CallInfo base_ci; /* CallInfo for first level (C calling Lua) */
16 volatile lua_Hook hook;
17 ptrdiff_t errfunc; /* current error handling function (stack index) */
18 int stacksize;
19 int basehookcount;
20 int hookcount;
21 unsigned short nny; /* number of non-yieldable calls in stack */
22 unsigned short nCcalls; /* number of nested C calls */
23 l_signalT hookmask;
24 lu_byte allowhook;
25};
lua_State 代表了 Lua 中的一个线程 (Lua 中的线程,指的就是一个 Coroutine),是暴露给用户的数据类型。从名字上看,它想表示一个 Lua 程序的执行状态,在官方文档中,它指代 Lua 的一个线程。每个线程拥有独立的数据栈以及函数调用链,还有独立的调试钩子和错误处理设施。
所以我们不应当简单的把 lua_State 看成一个静态的数据集,它是一组 Lua 程序的执行状态机。所有的 Lua C API 都是围绕这个状态机,改变其状态的:或把数据压入堆栈,或取出,或执行栈顶的函数,或继续上次被中断的执行过程。
top, stack, stack_last 都是和数据栈有关的变量,维护了栈的大小,以及当前的栈顶和栈底所在的位置。
ci, base_ci 则是和程序调用栈有关的变量,base_ci 可以理解为调用栈这一双向链表的头,ci 即双向链表的尾部,也是指向了当前正在执行的函数。
TValue & StkId
1/*
2** Union of all Lua values
3*/
4typedef union Value {
5 GCObject *gc; /* collectable objects */
6 void *p; /* light userdata */
7 int b; /* booleans */
8 lua_CFunction f; /* light C functions */
9 lua_Integer i; /* integer numbers */
10 lua_Number n; /* float numbers */
11} Value;
12
13#define TValuefields Value value_; int tt_
14
15typedef struct lua_TValue {
16 TValuefields;
17} TValue;
18
19typedef TValue *StkId; /* index to stack elements */
Lua 中的数据可以这样分为两类:值类型和引用类型。值类型可以被任意复制,而引用类型共享一份数据,由 GC 负责维护生命期。Lua 使用一个联合 union Value 来保存数据。
而 Lua 的数据栈,就只是由 TValue 构成的数组而已,而任何 Lua 中的对象,都可以存放在该数组中。
CallInfo
1typedef struct CallInfo {
2 StkId func; /* function index in the stack */
3 StkId top; /* top for this function */
4 struct CallInfo *previous, *next; /* dynamic call link */
5 union {
6 struct { /* only for Lua functions */
7 StkId base; /* base for this function */
8 const Instruction *savedpc;
9 } l;
10 struct { /* only for C functions */
11 lua_KFunction k; /* continuation in case of yields */
12 ptrdiff_t old_errfunc;
13 lua_KContext ctx; /* context info. in case of yields */
14 } c;
15 } u;
16 ptrdiff_t extra;
17 short nresults; /* expected number of results from this function */
18 unsigned short callstatus;
19} CallInfo;
Lua 把调用栈和数据栈分开保存。调用栈放在一个叫做 Calllnfo 的结构中,以双向链表的形式储存在线程对象里。
CallInfo 保存着正在调用的函数的运行状态。部分数据和函数的类型有关,以联合形式存放。C 函数与 Lua 函数的结构不完全相同。CallInfo 中还保存当前运行的函数在数据栈中对应的 base,top 等。
抽丝剥茧:关键的函数
Lua Stack
先来看看 lua_State 的栈有关的方法:
- stack_init 用于初始化 Lua 栈,这个函数通常在创建新的 Lua 状态时被调用,例如在
lua_newstate或lua_newthread中。 - luaD_growstack 用于在 Lua 栈空间不足时扩展 Lua 栈的大小,luaL_checkstack 这一公开 API,用于确保 Lua 栈上有足够的空间来容纳新的值,会在必要时,调用 growstack 来增加栈空间的大小。
- correctstack 用于在 Lua 栈的内存重新分配后更新栈上的指针,重新分配内存可能会改变栈的位置,这就需要更新所有指向栈上的指针。
stack_init
1static void stack_init (lua_State *L1, lua_State *L) {
2 int i; CallInfo *ci;
3 /* initialize stack array */
4 L1->stack = luaM_newvector(L, BASIC_STACK_SIZE, TValue);
5 L1->stacksize = BASIC_STACK_SIZE;
6 for (i = 0; i < BASIC_STACK_SIZE; i++)
7 setnilvalue(L1->stack + i); /* erase new stack */
8 L1->top = L1->stack;
9 L1->stack_last = L1->stack + L1->stacksize - EXTRA_STACK;
10 /* initialize first ci */
11 ci = &L1->base_ci;
12 ci->next = ci->previous = NULL;
13 ci->callstatus = 0;
14 ci->func = L1->top;
15 setnilvalue(L1->top++); /* 'function' entry for this 'ci' */
16 ci->top = L1->top + LUA_MINSTACK;
17 L1->ci = ci;
18}
函数的参数是两个 lua_State,分别是 L1 和 L。L1 是要初始化的 Lua 状态,L 是当前的 Lua 状态,该函数同样比较简单,就是分别初始化了lua_State 的数据栈和函数调用栈。
分配一个新的
TValue数组作为L1的数据栈,设置L1->stacksize的栈大小为BASIC_STACK_SIZE。并将L1的栈上的所有值设置为nil,设置L1->top = L1->stack的栈顶为栈的开始位置。初始化
L1的第一个CallInfo结构体ci,并设置L1->ci为ci。
luaD_growstack
1void luaD_growstack (lua_State *L, int n) {
2 int size = L->stacksize;
3 if (size > LUAI_MAXSTACK) /* error after extra size? */
4 luaD_throw(L, LUA_ERRERR);
5 else {
6 int needed = cast_int(L->top - L->stack) + n + EXTRA_STACK;
7 int newsize = 2 * size;
8 if (newsize > LUAI_MAXSTACK) newsize = LUAI_MAXSTACK;
9 if (newsize < needed) newsize = needed;
10 if (newsize > LUAI_MAXSTACK) { /* stack overflow? */
11 luaD_reallocstack(L, ERRORSTACKSIZE);
12 luaG_runerror(L, "stack overflow");
13 }
14 else
15 luaD_reallocstack(L, newsize);
16 }
17}
工作原理大致如下:
数组扩容时进行翻倍是个比较常见的处理方案呢(
- 计算新的栈大小。新的栈大小通常是当前栈大小的两倍,但如果当前栈大小已经很大,那么新的栈大小可能会小于当前栈大小的两倍。Lua 还会检查新的栈大小是否超过了最大的栈大小,如果超过了,Lua 就会抛出一个错误。
- 分配新的栈空间,并将旧的栈上的值复制到新的栈上。
- 释放旧的栈空间,并更新 Lua 状态中的栈指针和栈大小。
correctstack
1static void correctstack (lua_State *L, TValue *oldstack) {
2 CallInfo *ci;
3 UpVal *up;
4 L->top = (L->top - oldstack) + L->stack;
5 for (up = L->openupval; up != NULL; up = up->u.open.next)
6 up->v = (up->v - oldstack) + L->stack;
7 for (ci = L->ci; ci != NULL; ci = ci->previous) {
8 ci->top = (ci->top - oldstack) + L->stack;
9 ci->func = (ci->func - oldstack) + L->stack;
10 if (isLua(ci))
11 ci->u.l.base = (ci->u.l.base - oldstack) + L->stack;
12 }
13}
重新分配内存可能会改变栈的位置,这就需要更新所有指向栈上的指针,这也正是 correctstack 方法所做的。
- 遍历 Lua 状态中的所有指向栈上的指针,如
top、base、ci->func等。 - 对于每个指针,计算它在旧栈上的位置,然后将它更新为在新栈上的相同位置。
小结
Lua 的数据栈实际上是由 TValue 构成的数组,而调用栈实际上是 CallInfo 串成的双向链表,因此而对于操作系统而言,Lua 的运行时栈(纯 Lua 部分)总是在其嵌入的 C 语言的堆内存上的,而同一个 lua_State 共享了所有的数据栈和函数调用栈。
Virtual Stack
Lua 提供了常用的操作 Virtual Stack 的方法,不过大都是操作各种数据类型,我们来看几个典型:
- lua_gettop 获得 Virtual Stack 的栈顶位置
- index2addr 是一个较为重要的内部辅助函数 , 实现从数字到栈中地址的转换。
- lua_pushvalue 向 Virtual Stack 压入一个值
- lua_tolstring 从 Virtual Stack 中取出一个字符串
让我们先忽略源代码中涉及 gc 的部分和一些宏,观察 Lua 提供的操作 Virtual Stack 的 API 对应到 lua_State中真正的数据栈到底做了什么。
lua_gettop
1LUA_API int lua_gettop (lua_State *L) {
2 return cast_int(L->top - (L->ci->func + 1));
3}
lua_gettop 仅仅是计算里一下数据栈在 L->top 和 L->ci->func(不包含 L->ci->func,故 +1) 之间的 slot 的数量并返回。
index2addr
1static TValue *index2addr (lua_State *L, int idx) {
2 CallInfo *ci = L->ci;
3 if (idx > 0) {
4 TValue *o = ci->func + idx;
5 api_check(L, idx <= ci->top - (ci->func + 1), "unacceptable index");
6 if (o >= L->top) return NONVALIDVALUE;
7 else return o;
8 }
9 else if (!ispseudo(idx)) { /* negative index */
10 api_check(L, idx != 0 && -idx <= L->top - (ci->func + 1), "invalid index");
11 return L->top + idx;
12 }
13 else if (idx == LUA_REGISTRYINDEX)
14 return &G(L)->l_registry;
15 else { /* upvalues */
16 idx = LUA_REGISTRYINDEX - idx;
17 api_check(L, idx <= MAXUPVAL + 1, "upvalue index too large");
18 if (ttislcf(ci->func)) /* light C function? */
19 return NONVALIDVALUE; /* it has no upvalues */
20 else {
21 CClosure *func = clCvalue(ci->func);
22 return (idx <= func->nupvalues) ? &func->upvalue[idx-1] : NONVALIDVALUE;
23 }
24 }
25}
可以看到 index2addr 函数的返回值类型是 TValue *, 正好也是 StkId 所指向的类型。这个函数的作用是根据传入的索引,返回对应的数据栈中的地址。Lua 的 C API 使用 Virtual Stack 来传递参数和返回值。这个堆栈可以使用正数和负数索引。正数索引从堆栈底部开始(1 是堆栈的第一个元素),负数索引从堆栈顶部开始(-1 是堆栈的最后一个元素)。
- 如果索引是正数,并且小于或等于堆栈的当前大小,那么它直接返回对应的堆栈地址。
- 如果索引是负数,并且不小于堆栈的当前大小的负数,那么它返回从堆栈顶部开始的对应的堆栈地址。
- 如果索引是负数,并且小于堆栈的当前大小的负数,那么它返回一个特殊的 “伪索引”,这个伪索引可以用来访问全局环境或者当前线程的注册表 (和文章主题关系不大,可以先不管)。
- 如果索引超出了堆栈的范围,那么它返回一个无效的地址。
lua_pushvalue
1LUA_API void lua_pushvalue (lua_State *L, int idx) {
2 lua_lock(L);
3 setobj2s(L, L->top, index2addr(L, idx));
4 api_incr_top(L);
5 lua_unlock(L);
6}
lua_pushvalue 的实现也非常的简单,简单来讲,就是将值复制到 L->top ,并将 L->top +1。
lua_lock(L)/lua_unlock(L):这两个宏,用于在多线程环境中保护 Lua 状态。在单线程环境中,这个宏通常为空。setobj2s(L, L->top, index2addr(L, idx)):这是一个宏,用于将index2addr(L, idx)返回的地址处的值复制到L->top指向的地址。api_incr_top(L):这是一个宏,用于将L->top增加 1,也就是将栈顶向上移动一位。
lua_tolstring
1LUA_API const char *lua_tolstring (lua_State *L, int idx, size_t *len) {
2 StkId o = index2addr(L, idx);
3 if (!ttisstring(o)) {
4 if (!cvt2str(o)) { /* not convertible? */
5 if (len != NULL) *len = 0;
6 return NULL;
7 }
8 lua_lock(L); /* 'luaO_tostring' may create a new string */
9 luaO_tostring(L, o);
10 luaC_checkGC(L);
11 o = index2addr(L, idx); /* previous call may reallocate the stack */
12 lua_unlock(L);
13 }
14 if (len != NULL)
15 *len = vslen(o);
16 return svalue(o);
17}
lua_tolstring 用于将 Lua 栈上指定索引处的值转换为字符串,可以看出,内部使用 index2addr 将指定索引转换成 StkId, 然后对对应的值进行一系列判断和处理,并返回。中间重新获取 o 的地址,因为前面的调用可能会重新分配栈。
小结
看完了几个 Lua 提供的操作 Virtual Stack 的 API 代码实现,我们可以发现,这些 API 实际上主要都是都是对 lua_State 的 L->top 进行一些逻辑处理,而文档中提到的无论何时 Lua 调用 C,被调用的函数都得到一个新的栈,这个栈独立于 C 函数本身的栈,也独立于之前的 Lua 栈这一点也隐隐约约有所体现,index2addr 函数会校验 index 的范围符合要求。这一范围来自于 CallInfo 以及当前栈顶的共同约束。
OP_CALL
读完前两个小节,我们认识了 lua_State 的栈以及为 API 设计提供的 Virtual Stack,但是我们编写的一个 C_Function, 究竟是什么时候被如何执行的?lua_State 作为参数,而被调用的函数是怎么得到一个新的栈的?Virtual Stack 和 lua_State 里的栈依靠什么关联起来?这个问题的答案,就隐藏在我们 Lua 虚拟机中关于函数调用这一指令的实现中。
OP_CALL 干的事情主要都在 luaD_precall 中,除此之外 OP_CALL 就是解析 Lua 虚拟机的指令,取得函数和参数在栈上的数量 b,以及期望的返回值数量nresults 。如果 b 不为 0,调整栈顶的位置到函数和参数的后面,调用 luaD_precall 函数来准备调用。如果返回真,说明要调用的是 C 函数,如果 nresults 不小于 0,调整栈顶的位置到期望的返回值的后面。
1// lvm.c
2vmcase(OP_CALL) {
3 int b = GETARG_B(i);
4 int nresults = GETARG_C(i) - 1;
5 if (b != 0) L->top = ra+b; /* else previous instruction set top */
6 if (luaD_precall(L, ra, nresults)) { /* C function? */
7 if (nresults >= 0)
8 L->top = ci->top; /* adjust results */
9 Protect((void)0); /* update 'base' */
10 }
11 else { /* Lua function */
12 ci = L->ci;
13 goto newframe; /* restart luaV_execute over new Lua function */
14 }
15 vmbreak;
16}
在 luaD_precall 关键的一行 n = (*f)(L); 就是我们编写的 C_Function 真正调用的地方,在真正调用之前,Lua 做了如下的准备工作:
- 确保栈上有足够的空间来调用 C 函数。
- 获取下一个
CallInfo结构体,用于保存这次函数调用的信息。Whenever Lua calls C, it ensures that the stack has space for at least
LUA_MINSTACKextra slots.LUA_MINSTACKis defined as 20. Reference - 设置新的
CallInfo, 包括期望的返回值数量,真正执行的函数,对应的栈顶。
1// ldo.c
2int luaD_precall (lua_State *L, StkId func, int nresults) {
3 lua_CFunction f;
4 CallInfo *ci;
5 switch (ttype(func)) {
6 case LUA_TCCL: /* C closure */
7 f = clCvalue(func)->f;
8 goto Cfunc;
9 case LUA_TLCF: /* light C function */
10 f = fvalue(func);
11 Cfunc: {
12 int n; /* number of returns */
13 checkstackp(L, LUA_MINSTACK, func); /* ensure minimum stack size */
14 ci = next_ci(L); /* now 'enter' new function */
15 ci->nresults = nresults;
16 ci->func = func;
17 ci->top = L->top + LUA_MINSTACK;
18 lua_assert(ci->top <= L->stack_last);
19 ci->callstatus = 0;
20 if (L->hookmask & LUA_MASKCALL)
21 luaD_hook(L, LUA_HOOKCALL, -1);
22 lua_unlock(L);
23 n = (*f)(L); /* do the actual call */
24 lua_lock(L);
25 api_checknelems(L, n);
26 luaD_poscall(L, ci, L->top - n, n);
27 return 1;
28 }
29 case LUA_TLCL: { /* Lua function: prepare its call */
30 /* ...... */
31 }
32 default: { /* not a function */
33 checkstackp(L, 1, func); /* ensure space for metamethod */
34 tryfuncTM(L, func); /* try to get '__call' metamethod */
35 return luaD_precall(L, func, nresults); /* now it must be a function */
36 }
37 }
38}
从这里我们可以得出结论:Lua API 操作的 Virtual Stack 就是 lua_State 的堆栈。这个结论既出乎意料又合情合理。之前的困惑现在有了答案。Virtual Stack 基本上可以被理解为真正 lua_State 中堆栈的一个滑动窗口。再加上 index2addr 的验证保护,Lua 可以确保每次调用 C API 时都会在一个独立新的堆栈(窗口)中进行,而不会影响其他数据。这样的设计既高效又直观。
拨云见日:Lua 的 API 缘何如此设计?
至此,第一小节我对 Lua Stack 的全部问题都得到了解答,现在就可以来回顾一下:
Q1: Lua 提供的 API 基本上都围绕 Virtual Stack 所设计,但是这个 Virtual Stack 到底代表了什么?既然取名为 Stack,那么这个 Stack 和 Lua 的运行时的堆栈有什么关系?
A1: Virtual Stack 实际上就是 Lua 运行时的数据堆栈,但只能访问其中的部分,因此可以看作是 Lua 运行时数据栈的一个滑动窗口。
Q2: 第二段中提到,无论何时 Lua 调用 C,被调用的函数都得到一个新的栈,这又是如何做到的?这样做不会有很大的性能代价吗?
A2: 在调用 C 函数之前,Lua 会调整新的 CallInfo 变量,使得被调用的函数只能看到原来数据栈的一部分内容。因此,在抽象意义上为每个调用的函数分配了一个新的栈,并且不会有性能代价,因为没有内存重新分配等操作(当然,如果栈空间不足时仍会重新分配)。
Q3: 从给出的 C 例程看,从 Lua 代码中传入的参数,被依次压入到 Lua 提供的 Virtual Stack 中,C 层需要返回给 Lua 层的结果也被依次的压入该 Virtual Stack, 该函数在将结果推入栈之前不需要对栈进行额外的处理,这又是如何做到的?
A3: 感兴趣的读者可以自行查看 luaD_poscall 这个方法(
我所理解的 Lua API Stack 的设计理念
- 简单性:栈是一种非常简单且易于理解的数据结构。基于栈的 API 可以让用户只需要关心如何操作栈顶的元素,而不需要关心其他复杂的内存管理问题。
- 灵活性:栈模型可以很容易地支持变长参数和多返回值,这在很多其他 API 设计中是难以实现的。
- 效率:栈操作对于 Lua 而言比其他数据结构的操作更加高效。Lua 的执行是在这一栈上(Lua 是一个寄存器虚拟机,但是其寄存器在我的理解中就是 Lua 的 Stack),这种设计使得 Lua 在处理函数调用、参数传递和返回值时能够更高效地执行。
最后,本文介绍了 Lua 中的栈。希望能帮助读者更好地理解 Lua C API 中栈的设计目的和用法。实际上,Lua 的协程(Coroutine)与栈密切相关,并包含着非常精巧的设计。受限于主题和个人水平,只能在日后有更深入理解时再展开讨论。文末给出的参考文章实在是给了我非常多的指点,欢迎感兴趣的读者前往阅读。